PCF - 12 factor design pattern
what are the 12 Factor Design patterns? Could you list each one from memory?
The twelve-factor app is a methodology for building software-as-a-service apps that use declarative formats for automation, have clean contract with underlying OS, are suitable for cloud deployment, have continuous deployment and can scale up.
Below are the 12 factors:
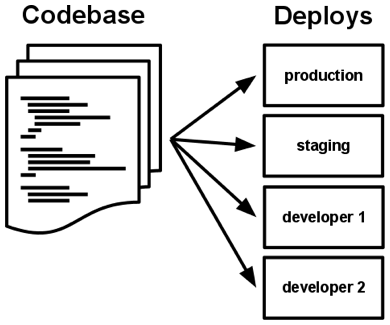
I. Codebase
One codebase tracked in revision control, many deploys.
There is only one codebase per app, but there will be many deploys of the app.
Explicitly declare and isolate dependencies
A twelve-factor app never relies on implicit existence of system-wide packages. It declares all dependencies, completely and exactly, via a dependency declaration manifest.
III. Config
Store config in the environment
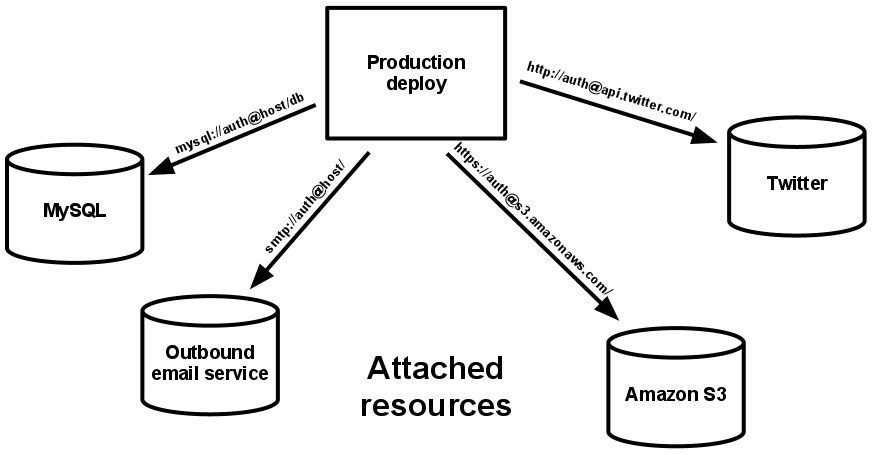
Treat backing services as attached resources
A backing service is any service the app consumes over the network as part of its normal operation. Examples include datastores (such as MySQL or CouchDB), messaging/queueing systems (such as RabbitMQ or Beanstalkd), SMTP services for outbound email (such as Postfix), and caching systems (such as Memcached).
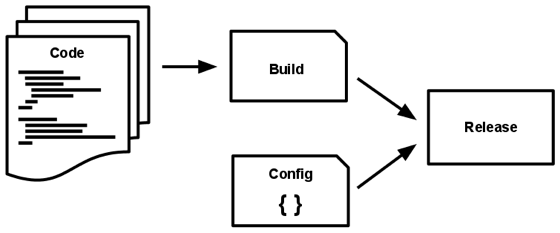
V. Build, release, run
Strictly separate build and run stages
VI. Processes
Execute the app as one or more stateless processes
Twelve-factor processes are stateless and share-nothing. Any data that needs to persist must be stored in a stateful backing service, typically a database.
The memory space or filesystem of the process can be used as a brief, single-transaction cache. The twelve-factor app never assumes that anything cached in memory or on disk will be available on a future request or job – with many processes of each type running, chances are high that a future request will be served by a different process.
Sticky sessions are a violation of twelve-factor and should never be used or relied upon. Session state data is a good candidate for a datastore that offers time-expiration, such as Memcached or Redis.
VII. Port binding
Export services via port binding
The twelve-factor app is completely self-contained and does not rely on runtime injection of a webserver into the execution environment to create a web-facing service. The web app exports HTTP as a service by binding to a port, and listening to requests coming in on that port.
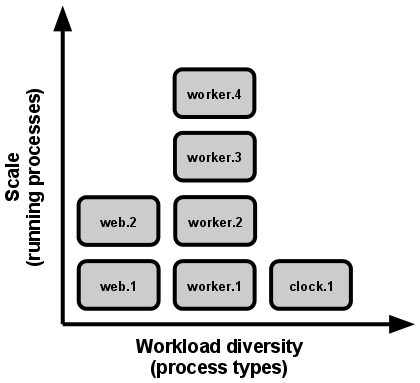
VIII. Concurrency
Scale out via the process model
In the twelve-factor app, processes are a first class citizen. Processes in the twelve-factor app take strong cues from the unix process model for running service daemons. Using this model, the developer can architect their app to handle diverse workloads by assigning each type of work to a process type. For example, HTTP requests may be handled by a web process, and long-running background tasks handled by a worker process.
IX. Disposability
Maximize robustness with fast startup and graceful shutdown
The twelve-factor app’s processes are disposable, meaning they can be started or stopped at a moment’s notice. This facilitates fast elastic scaling, rapid deployment of code or config changes, and robustness of production deploys.
X. Dev/prod parity
Keep development, staging, and production as similar as possible
XI. Logs
Treat logs as event streams
XII. Admin processes
Run admin/management tasks as one-off processes
One-off admin processes should be run in an identical environment as the regular long-running processes of the app. They run against a release, using the same codebase and config as any process run against that release. Admin code must ship with application code to avoid synchronization issues.
The twelve-factor app is a methodology for building software-as-a-service apps that use declarative formats for automation, have clean contract with underlying OS, are suitable for cloud deployment, have continuous deployment and can scale up.
Below are the 12 factors:
I. Codebase
One codebase tracked in revision control, many deploys.
There is only one codebase per app, but there will be many deploys of the app.
There is always a one-to-one correlation between the codebase and the app:
- If there are multiple codebases, it’s not an app – it’s a distributed system. Each component in a distributed system is an app, and each can individually comply with twelve-factor.
- Multiple apps sharing the same code is a violation of twelve-factor. The solution here is to factor shared code into libraries which can be included through the dependency manager.
Explicitly declare and isolate dependencies
A twelve-factor app never relies on implicit existence of system-wide packages. It declares all dependencies, completely and exactly, via a dependency declaration manifest.
III. Config
Store config in the environment
An app’s config is everything that is likely to vary between deploys (staging, production, developer environments, etc). This includes:
- Resource handles to the database, Memcached, and other backing services
- Credentials to external services such as Amazon S3 or Twitter
- Per-deploy values such as the canonical hostname for the deploy
Treat backing services as attached resources
A backing service is any service the app consumes over the network as part of its normal operation. Examples include datastores (such as MySQL or CouchDB), messaging/queueing systems (such as RabbitMQ or Beanstalkd), SMTP services for outbound email (such as Postfix), and caching systems (such as Memcached).
V. Build, release, run
Strictly separate build and run stages
A codebase is transformed into a (non-development) deploy through three stages:
- The build stage is a transform which converts a code repo into an executable bundle known as a build. Using a version of the code at a commit specified by the deployment process, the build stage fetches vendors dependencies and compiles binaries and assets.
- The release stage takes the build produced by the build stage and combines it with the deploy’s current config. The resulting release contains both the build and the config and is ready for immediate execution in the execution environment.
- The run stage (also known as “runtime”) runs the app in the execution environment, by launching some set of the app’s processes against a selected release.
VI. Processes
Execute the app as one or more stateless processes
Twelve-factor processes are stateless and share-nothing. Any data that needs to persist must be stored in a stateful backing service, typically a database.
The memory space or filesystem of the process can be used as a brief, single-transaction cache. The twelve-factor app never assumes that anything cached in memory or on disk will be available on a future request or job – with many processes of each type running, chances are high that a future request will be served by a different process.
Sticky sessions are a violation of twelve-factor and should never be used or relied upon. Session state data is a good candidate for a datastore that offers time-expiration, such as Memcached or Redis.
VII. Port binding
Export services via port binding
The twelve-factor app is completely self-contained and does not rely on runtime injection of a webserver into the execution environment to create a web-facing service. The web app exports HTTP as a service by binding to a port, and listening to requests coming in on that port.
VIII. Concurrency
Scale out via the process model
In the twelve-factor app, processes are a first class citizen. Processes in the twelve-factor app take strong cues from the unix process model for running service daemons. Using this model, the developer can architect their app to handle diverse workloads by assigning each type of work to a process type. For example, HTTP requests may be handled by a web process, and long-running background tasks handled by a worker process.
IX. Disposability
Maximize robustness with fast startup and graceful shutdown
The twelve-factor app’s processes are disposable, meaning they can be started or stopped at a moment’s notice. This facilitates fast elastic scaling, rapid deployment of code or config changes, and robustness of production deploys.
- Processes should strive to minimize startup time.
- Processes shut down gracefully when they receive a SIGTERM signal from the process manager.
- For a worker process, graceful shutdown is achieved by returning the current job to the work queue.
- Processes should also be robust against sudden death, in the case of a failure in the underlying hardware.
- A twelve-factor app is architected to handle unexpected, non-graceful terminations. Crash-only design takes this concept to its logical conclusion.
X. Dev/prod parity
Keep development, staging, and production as similar as possible
The twelve-factor app is designed for continuous deployment by keeping the gap between development and production small.
- Make the time gap small: a developer may write code and have it deployed hours or even just minutes later.
- Make the personnel gap small: developers who wrote code are closely involved in deploying it and watching its behavior in production.
- Make the tools gap small: keep development and production as similar as possible.
Treat logs as event streams
A twelve-factor app never concerns itself with routing or storage of its output stream.
It should not attempt to write to or manage logfiles. Instead, each running process writes its event stream, unbuffered, to
stdout. During local development, the developer will view this stream in the foreground of their terminal to observe the app’s behavior.
In staging or production deploys, each process’ stream will be captured by the execution environment, collated together with all other streams from the app, and routed to one or more final destinations for viewing and long-term archival. These archival destinations are not visible to or configurable by the app, and instead are completely managed by the execution environment. Open-source log routers (such as Logplex and Fluent) are available for this purpose.
The event stream for an app can be routed to a file, or watched via realtime tail in a terminal. Most significantly, the stream can be sent to a log indexing and analysis system such as Splunk, or a general-purpose data warehousing system such as Hadoop/Hive.
XII. Admin processes
Run admin/management tasks as one-off processes
One-off admin processes should be run in an identical environment as the regular long-running processes of the app. They run against a release, using the same codebase and config as any process run against that release. Admin code must ship with application code to avoid synchronization issues.



Comments
Post a Comment